浅析虚拟机软件仿真中的解释技术¶
主要贡献者
- 作者:@zevorn
- 原文:浅析虚拟机软件仿真中的解释技术 - 泽文
本文总结了《虚拟机 - 系统与进程的通用平台》一书中与解释技术相关的内容。
前言(背景介绍)¶
虚拟机经常利用软件仿真技术(指令集仿真)来模拟客户程序。既有源 ISA 和 目标 ISA 相同的情况,也有不同的情况。一般我们对翻译到不同体系结构的场景更感兴趣,我们讨论的重心也集中在指令集仿真方面。
虚拟机常见的指令集仿真技术有两种:解释技术和二进制翻译技术。
前者典型的项目有 Simics 的解释执行模式、QEMU 的 TCI、NEMU 等;后者典型的项目有 QEMU 的 TCG,另外也有基于 LLVM-JIT 实现的二进制翻译引擎,比如 SkyEye 的动态翻译模式。
本文先讨论解释技术的实现,这是一种相对更轻量、更简洁的方案。
一般来说,解释技术主要模拟了 CPU 取指译码执行的流程,可以总结为:取一条源指令,对其进行分析,执行需要的操作,再取下一条源指令这样一个循环的过程。下面介绍几种经典的解释技术,比如基本解释、线索解释等。
基本解释(译码 - 分派)¶
狭义上,一个解释器程序首先是宿主机平台上的用户态进程,它能够模拟客户机程序(或者叫源程序)所需要的完整结构状态,这些状态包括所有的结构寄存器和主存。
而客户机程序的内存映像,主要是程序代码和程序数据,都被维护在解释器进程的内存中,如下图所示:
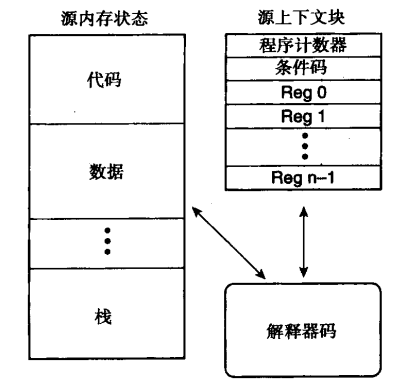
客户机的结构寄存器一般被称为上下文块(context block),由一张表构成,同样由解释器进行维护,它包含了客户机体系结构规定的通用寄存器、程序计数器、条件码、系统控制寄存器等部件。
指令解释的结果,会作用到上下文块,更新内部的数据,或者直接更新客户机内存。
上文提到的解释循环执行的过程,是典型的译码 - 分派(decode-and-dispatch)解释器。它的特点是:
-
围绕一个主循环来展开,是一个典型的状态机模型;
-
对源程序的指令逐条执行,并分派给基于指令类型的解释例程。
我们以 YEMU(一个简单的 CPU 模拟器)为例,进行补充讲解,下面给出摘要代码:
/* 上下文块 */
uint8_t pc = 0; // PC, C 语言中没有 4 位的数据类型,我们采用 8 位类型来表示
uint8_t R[NREG] = {}; // 寄存器
/* 内存,其中包含一个计算 z = x + y 的程序,这是一个自定义的指令集,方便演示 */
uint8_t M[NMEM] = {
0b11100110, // load 6# | R[0] <- M[y]
0b00000100, // mov r1, r0 | R[1] <- R[0]
0b11100101, // load 5# | R[0] <- M[x]
0b00010001, // add r0, r1 | R[0] <- R[0] + R[1]
0b11110111, // store 7# | M[z] <- R[0]
0b00010000, // x = 16
0b00100001, // y = 33
0b00000000, // z = 0
};
int halt = 0; // 结束标志
#define DECODE_R(inst) uint8_t rt = (inst).rtype.rt, rs = (inst).rtype.rs
#define DECODE_M(inst) uint8_t addr = (inst).mtype.addr
// 执行一条指令
void exec_once() {
inst_t this;
this.inst = M[pc]; // 取指
switch (this.rtype.op) {
// 操作码译码 操作数译码 执行
case 0b0000: { DECODE_R(this); R[rt] = R[rs]; break; }
case 0b0001: { DECODE_R(this); R[rt] += R[rs]; break; }
case 0b1110: { DECODE_M(this); R[0] = M[addr]; break; }
case 0b1111: { DECODE_M(this); M[addr] = R[0]; break; }
default:
printf("Invalid instruction with opcode = %x, halting...\n", this.rtype.op);
halt = 1;
break;
}
pc++; // 更新 PC
}
int main() {
while (1) {
exec_once();
if (halt) break;
}
printf("The result of 16 + 33 is %d\n", M[7]);
return 0;
}
这段代码很简单。
main() 函数中定义了 while 循环代码块,通过 halt 来 break,防止死循环。
解释器的主体代码放在 exec_once() 子函数中,包含了基本的取指、译码、执行指令语义的操作,执行的结果更新到上下文块(通用寄存器),最后再更新程序计数器 PC,然后继续下一个循环。
即使更复杂的解释器,也基本按照这个流程来实现。
另外我们可以在 while 循环中增加人机交互操作,方便用户介入。这也体现了解释器一个显著特点,即强大且灵活的调试能力(单步执行、回溯执行、场景保存及恢复等)。
对于虚拟机来说,客户机的一切都是透明的(都驻留在虚拟机进程的内存中),而解释技术又能很方便的控制和观测客户机的状态,相比硬件调试器,少了很多限制。
虽然解释器的过程很简单,但解释的性能代价相当高。
我们希望解释源指令使用的目标指令越少越好,理想情况下,一条源指令对应到一条目标指令。
但很显然,即使解释器代码直接用汇编语言来写,解释一条加法这种简单指令,仍然需要目标 ISA 中数十条指令来执行。
且在解释器的主循环里,包含了很多直接和间接的分支指令,它们会影响宿主机硬件处理器的分支预测性能。
同时,由于源指令和上下文都保存在内存里,解释指令的过程,需要频繁的访存,这会带来进一步的性能开销。
接下来介绍的几种解释技术,目的就是降低或消除译码分派解释技术中影响性能的环节。
线索解释(优化跳转)¶
译码分派解释器中包含了很多直接和间接的分支指令,仍然以 YEMU 程序为例,主要包含:
-
主循环的人机交互或者中断的分支,比如处理 halt 的 if & break 语句;
-
针对 switch case 语句的分支,比如 exec_once() 中 switch 译码到指令实现的语句;
-
从指令实现返回上层循环的分支,比如从 break 返回 exec_once() 末尾,再返回到上层 while 循环的语句。
我们先不考虑第 1 点,为了消除这些分支,我们可以将指令的特征线索搜集到一张表中,线索特征常根据指令的编码格式来提取,比如 RISC-V 指令格式有 R-type、I-type、U-type 等。
一般是把线索特征作为分派表的索引,表项存着指令实现的解释器例程或者子程序段,为了减少函数调用开销(出栈入栈,函数调用的上下文切换),可以用 goto 进行跳转,因此可以在表项中直接存标签地址。
如此,我们可以把第 2 点的 switch case 分支消除掉,同时为了进一步消除第 3 点,我们可以在指令实现的尾部追加分派表的查找操作,并直接跳转到下一条解释器例程。
下面给出代码示例:
int main(void) {
/* 利用一元操作符 && 获取标号的地址,提高移植性 */
static const void *dispatch[INSN_MAX] = {
[0b0000] = &&_insn_mov,
[0b0001] = &&_insn_add,
[0b1110] = &&_insn_load,
[0b1111] = &&_insn_store,
/* other insn */
};
inst_t this;
this.inst = M[pc]; // 取指
goto *dipatch[this.rtype.op]; // 分派表获取解释器例程对应的 label 地址,并跳转过去
_insn_mov:
DECODE_R(this);
R[rt] = R[rs];
this.inst = M[++pc]; // 取指
goto *dipatch[this.rtype.op];
_insn_add:
DECODE_R(this);
R[rt] += R[rs];
this.inst = M[++pc]; // 取指
goto *dipatch[this.rtype.op];
_insn_load:
DECODE_M(this);
R[0] = M[addr];
this.inst = M[++pc]; // 取指
goto *dipatch[this.rtype.op];
_insn_store:
DECODE_M(this);
M[addr] = R[0];
this.inst = M[++pc]; // 取指
goto *dipatch[this.rtype.op];
// 结束的地方,这里暂时没有实现 halt
return 0;
}
可以看到,使用线索解释以后,就不再需要主分派循环了。
下图说明了译码 - 分派方法和刚刚描述的线索解释器技术在数据和控制流方面的区别。
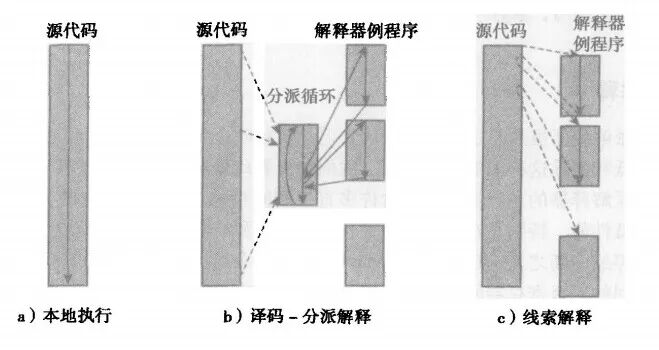
对于译码 - 分派解释,控制流不断地退出和返回主分派循环。
而线索解释将下一个循环的取指译码操作复制到了每个解释器程序中,因此,这种场景下的解释器例程不再是通常意义上的子程序,而是由线索串起来的简单代码块。
所以,线索解释的关键点,就是分派的动作是通过一张表间接完成的。这种间接的优势之一就是解释器例程可以独立的修改和重定位。由于通过分派表的跳转是间接的,这种方式便被称为间接线索解释(Dewar 1975)。
预译码和直接线索解释¶
尽管间接线索解释器消除了集中分派循环,但分派表还是会带来开销。
在这个表中查找一个解释器例程,仍然需要访存和寄存器间接分支指令。为了获得更高的效率,我们可以尝试消除这个分派表。
我们知道,指令集的数量通常是有限的,对于一个程序,存在大量相同的指令。进一步观察,在间接线索解释器的场景中,每次遇到一个指令,都会调用一个解释器例程,这样当同一源指令被解释多次时,它的每一步都是被重复执行的。
我们可以提取这些关键信息,以中间形式缓存,然后在这条指令每次被仿真时,复用这些关键信息,省去中间多余的操作。这个更高效的过程,被称为预译码(predecoding)。
可以看出,预译码给出了一种更加高效的线索解释技术——直接线索解释(direct threaded interpretation, Bell 1973,Kogge 1982)。
我们先聊聊基本的预译码操作。
预译码涉及解析一条指令的关键信息,并把它存储在易于访问的域中(Magnusson 和 Samuelsson 1994,Laru 1991),比如 cache,或者内存对齐的区域。
例如 PowerPC 的 ALU 指令(and、or、add、subtract),都是通过操作码位和扩展操作码位的联合来指明,它们都具有相同的操作码(31),并通过指令字的低端距离操作码较远的扩展操作码位来区别。
而预译码可以将这些信息,组合成单一的操作码,寄存器标识符,也可以从源二进制代码中对应指令数据里提取出来,放入按照字节对其的域中,以便取字节指令直接访问。
从指令提取的关键信息,一般组织成易于解释器访问的中间形式,通常不如源指令集格式的信息密集,但更方便解析。
下面继续以 PowerPC 的程序段为例,作进一步讲解:
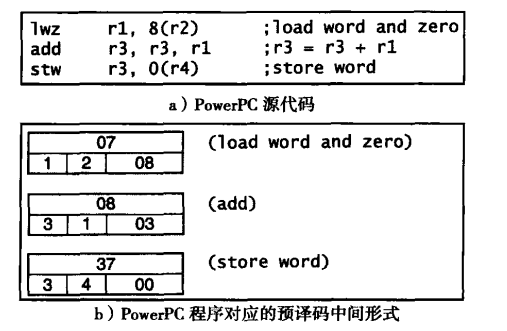
a) 包含了一小段 PowerPC 代码序列,这个序列从内存中读取数据项并加载到寄存器中,最后累加得到一个和。再把这个和写回内存。
b) 是 a) 相同代码的中间形式。这种预译码格式,用一个单字,对指令操作编码。它按照前面讨论的形式组合而来,因此这些编码不必和源操作码保持一致。
一个经典的实现,就是 QEMU 的 decodetree,它将指令译码以后的中间形式,保存在指令型结构体中,下面是 QEMU decodetree 对 PowerPC 指令译码的中间形式保存示例:
typedef struct {
int frt;
int fra;
int frb;
int frc;
bool rc;
} arg_A;
typedef struct {
int rt;
int ra;
uint64_t ui;
} arg_D_ui;
typedef struct {
int vrt;
int vra;
int vrb;
int rc;
} arg_VA;
更进一步地,可以将指令型结构体组织成一个数组,来缓存中间代码。
为了方便从数组里面访问,可以把访问数组的下标作为新的目标程序计数器(TPC),同时,源 ISA 的程序计数器(SPC)仍被维持着,以便从内存里访问源程序段。
一般地,对于长度不定的 CISC 指令,TPC 和 SPC 的值,在任意给定时间内可以不具有明显的关系,因此有必要对二者进行维护。
对于长度固定的 RISC 指令,这种关系很容易计算出来,所提供的中间形式,也是固定长度的。
我们最后再聊聊直接线索解释器的实现。
为了去除间接线索解释器分派表查找的中间层,避免每次的内存访问,我们可以直接把解释器例程的实际地址替换中间代码中的指令代码(Bell 1973)。
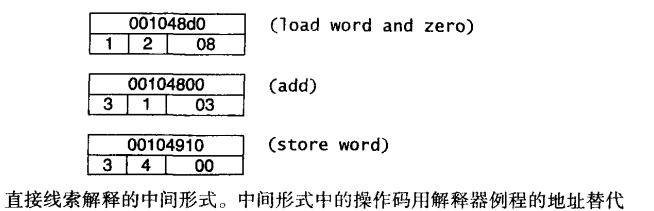
下面对 YEMU 代码作进一步优化,实现如下:
struct insn_info {
void *op; // 存放解释例程的实际地址,比如 &&_insn_mov
unsigned char dest;
unsigned char src1;
unsigned char src2;
} code[INSN_MAX];
int main(void) {
/* ... */
_insn_mov:
int rt = code[tpc].dest;
int rs = code[tpc].src1;
R[rt] = R[rs];
spc++;
tpc++;
goto *code[tpc].op;
/* ... */
return 0;
}
对于 C 语言的实现,仍然可以利用 GCC 编译器的特性,使用 && 符号来获取标号地址,这样可以使解释器具备重定位的特点。
值得补充的是,不管是间接线索解释器的分派表,还是直接线索解释器的中间形式,由于内部解释器例程的可替换的特性,我们可以很方便地实现许多调试手段。
比如打断点的功能,类似 GDB 的断点流程,可以将分派表或者中间代码的某条指令替换成解释器可以识别的特殊指令,当解释器执行到这条特殊指令时,执行暂停操作,然后再把指令替换成原指令。