GPU 发展历史¶
主要贡献者
- 作者:@zevorn
GPU(Graphics Processing Unit)从最初的图形加速硬件,发展为通用并行计算引擎,再演进为支撑万亿参数大模型的 AI 算力基础设施,其技术演进深刻影响了整个计算产业。本章将从三个历史阶段出发,梳理 GPU 的发展脉络,帮助你建立对 GPU 体系结构的全局认知——这也是理解训练营中 GPGPU 建模、CXL 加速器仿真等课程的重要前置知识。
概览
- 早期 GPU:从图形加速到可编程着色器
- CUDA 时期:通用计算革命与深度学习崛起
- 超节点互联:AI 工厂时代的算力基础设施
早期 GPU(1960s–2006)¶
图形加速的起源¶
计算机图形学的故事,要从 1963 年讲起。
 Ivan Sutherland 在 TX-2 计算机上操作 Sketchpad 系统(1963)
Ivan Sutherland 在 TX-2 计算机上操作 Sketchpad 系统(1963)
这一年,Ivan Sutherland 在 MIT 完成了他的博士论文,发明了 Sketchpad——人类历史上第一个交互式计算机图形程序。用户通过光笔在 CRT 屏幕上直接绘图,支持约束关系、图形复制、旋转和缩放。Sutherland 由此被公认为"计算机图形学之父",并于 1988 年获得 ACM 图灵奖。
 NASA Ames 研究中心的 IBM 2250 计算机工作站(1973)
NASA Ames 研究中心的 IBM 2250 计算机工作站(1973)
几乎同一时期,1964 年随 IBM System/360 发布的 IBM 2250 图形显示单元,成为最早的图形加速硬件之一。它采用矢量图形方式,在 1024x1024 的网格上以线段形式绘图,以每秒最多 40 次的频率刷新 CRT 显示——尽管原始,但已经体现了"图形处理与显示分离"的早期思想。
1968 年,David Evans 与 Ivan Sutherland 在犹他大学创立了 Evans & Sutherland (E&S),开发了一系列图形工作站,成为 SGI 出现之前图形领域的标杆。犹他大学的图形实验室还培养了一批关键人才,其中就包括后来创立 SGI 的 Jim Clark。
 SGI Indigo 图形工作站,曾是专业图形领域的标志性产品
SGI Indigo 图形工作站,曾是专业图形领域的标志性产品
Jim Clark 在斯坦福大学任教期间,于 1979 年与学生共同开发了 Geometry Engine——第一个 VLSI 实现的几何流水线芯片,专门加速 3D 图形渲染所需的几何运算。1982 年,Clark 带领 7 名斯坦福研究生创立了 Silicon Graphics (SGI),次年发布首款产品 IRIS 1000 图形终端及配套的 IRIS GL 图形库。此后的十余年间,SGI 工作站成为电影特效(《侏罗纪公园》)、科学可视化、飞行模拟等领域的标准平台。
1992 年,SGI 将其私有的 IRIS GL 开放标准化为 OpenGL 1.0,由 Mark Segal 和 Kurt Akeley 主导编写规范,并成立了 OpenGL Architecture Review Board (ARB) 进行行业共管。这是图形学走向开放标准的里程碑,也为后来理解 GPU API 虚拟化(如 virtio-gpu、virglrenderer)奠定了历史基础。
消费级 GPU 的崛起¶
20 世纪 90 年代中期,3D 图形加速从专业工作站走向消费市场,三家公司的竞争塑造了现代 GPU 的雏形。
3dfx 与 Voodoo 革命
 基于 3dfx Voodoo Graphics 芯片的 Orchid Righteous 3D 加速卡
基于 3dfx Voodoo Graphics 芯片的 Orchid Righteous 3D 加速卡
1994 年,Ross Smith、Gary Tarolli、Scott Sellers(三人均为 SGI 前员工)创立了 3dfx Interactive。1996 年 11 月发布的 Voodoo Graphics 是一块仅做 3D 加速的附加卡(需要通过 VGA 线缆与独立的 2D 显卡串联),但效果革命性——几乎一夜之间让大量 2D 显卡过时。3dfx 凭借自研的 Glide API 和出色的性能,一度占据 3D 加速器市场 80–85% 的份额。1998 年的 Voodoo2 更支持 SLI 双卡并行,进一步巩固了市场地位。
然而,3dfx 在 1998 年收购 OEM 厂商 STB Systems 后陷入战略失误,Voodoo 5 延期交付且性能落后于竞争对手。2000 年末,3dfx 资产被出售给 NVIDIA,2002 年正式破产。
NVIDIA 的创立与崛起
 位于圣何塞 Berryessa Road 的 Denny's 餐厅——NVIDIA 三位创始人在此决定创业
位于圣何塞 Berryessa Road 的 Denny's 餐厅——NVIDIA 三位创始人在此决定创业
1993 年,Jensen Huang(黄仁勋)、Chris Malachowsky 和 Curtis Priem 三人在北加州一家 Denny's 餐厅讨论创业愿景——"在 PC 上实现逼真的 3D 图形"。起步资金仅 4 万美元,最初在 Priem 位于 Fremont 的联排别墅中工作。那家 Denny's 餐厅后来挂上了铭牌:"The NVIDIA Booth — The booth that launched a trillion-dollar company"。
NVIDIA 的第一款产品 NV1(1995)采用了四次曲面纹理映射(quadratic texture mapping)而非业界主流的多边形渲染,这是一个致命的技术路线错误——Microsoft 随后发布了基于三角形的 DirectX 规范,NV1 立刻与行业标准不兼容。NVIDIA 陷入财务困境,靠 Sega 的 700 万美元预付款续命。
转折发生在 1997 年。RIVA 128(NV3)转向三角形渲染,成为首款兼容 DirectX 的产品,扭转了局面。随后的 RIVA TNT(1998)和 RIVA TNT2(1999)进一步站稳脚跟。
 NVIDIA GeForce 256 (NV10) 芯片——被宣传为"世界上第一个 GPU"
NVIDIA GeForce 256 (NV10) 芯片——被宣传为"世界上第一个 GPU"
1999 年 8 月,NVIDIA 发布了 GeForce 256(NV10),并将其宣传为"世界上第一个 GPU"。NVIDIA 定义了 GPU 一词的含义:"一个集成了变换、光照、三角形设置/裁剪和渲染引擎的单芯片处理器,能够每秒处理至少 1000 万个多边形。"其关键创新是硬件 Transform & Lighting (T&L) 引擎,将几何变换和光照计算从 CPU 卸载到 GPU,这是固定功能管线的巅峰之作。
ATI 与 Radeon 系列
1985 年,Kwok Yuen Ho 等人在加拿大安大略省创立了 ATI Technologies。2000 年发布的 Radeon R100 引入了 HyperZ 带宽优化技术,正式与 NVIDIA GeForce 2 展开竞争。2002 年 8 月,Radeon 9700 Pro(R300)成为第一款完全支持 DirectX 9.0 的消费级 GPU,这是一个重要的里程碑。
架构演进里程碑¶
GPU 架构在短短十年间经历了三次根本性变革,每一次都大幅拓展了 GPU 的能力边界。
固定功能管线时代(~1996–2000)
这一时期的 GPU,光照方程、纹理混合、几何变换等操作全部"烧入硅片",硬件预定义,开发者无法自定义渲染效果。代表产品包括 3dfx Voodoo(1996)、NVIDIA RIVA 系列(1997–1999)和 GeForce 256 的 T&L 引擎(1999)。
可编程着色器的引入(2001)
2001 年 2 月发布的 GeForce 3(NV20)是图形学历史的关键转折点——第一款具有真正可编程性的 GPU。它支持 DirectX 8.0 的像素着色器和顶点着色器(市场名称"nFinite FX Engine"),硬件配置为 4 个像素着色器和 1 个顶点着色器,5700 万晶体管。
自此,开发者可以编写自定义着色器程序来控制渲染效果,GPU 从"专用加速器"向"可编程处理器"迈出了关键一步。此后的 DirectX 版本与 Shader Model 快速演进:
| 时间 | DirectX | Shader Model | 代表 GPU |
|---|---|---|---|
| 1999 | DX 7.0 | 无(固定管线 T&L) | GeForce 256 |
| 2000 | DX 8.0 | SM 1.0 | GeForce 3 (NV20) |
| 2002 | DX 9.0 | SM 2.0 | Radeon 9700 (R300) |
| 2004 | DX 9.0c | SM 3.0 | GeForce 6800 (NV40) |
| 2006 | DX 10.0 | SM 4.0 | GeForce 8800 (G80) |
统一着色器架构的诞生(2005–2006)
在 SM 3.0 及之前,顶点着色器和像素着色器是物理分离的硬件单元,各自有固定数量。当场景中顶点运算量大而像素运算量小时(或反之),一部分硬件就会空闲,造成利用率低下。
2005 年 11 月,ATI 为 Microsoft Xbox 360 定制设计的 Xenos GPU 成为人类历史上第一个采用统一着色器架构的 GPU。它拥有 48 个统一着色器处理器,同一组硬件单元可以动态分配执行顶点、像素或几何着色器任务,大幅提升了利用率。
 NVIDIA G80 芯片高分辨率 die shot,可以看到 128 个流处理器的排列
NVIDIA G80 芯片高分辨率 die shot,可以看到 128 个流处理器的排列
2006 年 11 月 8 日,NVIDIA 发布 GeForce 8800 GTX(G80)——PC 平台上第一款统一着色器架构 GPU,支持 DirectX 10 / SM 4.0。它拥有 128 个流处理器、6.81 亿晶体管、480mm² 的芯片面积(当时商用 GPU 最大的芯片)。此后,所有主流 GPU 均采用统一架构。
Note
统一着色器架构的意义不仅限于图形渲染。当同一组硬件单元可以执行任意类型的着色器程序时,距离执行通用计算程序就只有一步之遥——这正是 CUDA 诞生的硬件基础。
早期 GPGPU 探索¶
2001 年可编程着色器引入后,研究者敏锐地发现 GPU 的大规模并行浮点运算能力可以用于图形渲染以外的通用计算。但早期的 GPGPU 需要将计算问题"伪装"成图形问题——用纹理(texture)表示数据数组,用着色器程序(shader program)执行计算,用渲染到纹理(render-to-texture)获取结果。编程极其繁琐,调试困难,错误处理几乎不存在。
2002 年,Mark Harris 创造了 GPGPU(General-Purpose computing on Graphics Processing Units)这个术语,并创建了 gpgpu.org 网站,成为早期社区的核心。
2004 年,斯坦福大学博士生 Ian Buck 发布了 BrookGPU——一个基于 ANSI C 的流编程语言和编译器/运行时系统,让程序员无需了解图形 API 就能利用 GPU 进行通用计算。BrookGPU 是 CUDA 的直接前身。2005 年,NVIDIA 从斯坦福招募了 Ian Buck,他加入 NVIDIA 后启动了 CUDA 项目,将 GPU 通用计算从学术探索推向产业化。
CUDA 时期(2006–2017)¶
CUDA 的诞生¶
2006 年 11 月 8 日,NVIDIA CEO Jensen Huang 在新闻发布会上揭开了 CUDA 的面纱。同日发布的 GeForce 8800 GTX(G80)不仅是第一款统一着色器架构的消费级 GPU,也是第一款 CUDA 兼容的 GPU。
CUDA Toolkit 1.0 于 2007 年 6 月正式发布,包含 NVCC C 编译器、CUBLAS 线性代数库和 CUFFT 快速傅里叶变换库。从此,开发者可以使用类似 C 的编程语言直接在 GPU 上编写并行程序,彻底告别了将计算问题"伪装"成图形操作的痛苦时代。
CUDA 引入了清晰的编程抽象:线程层次结构(Thread → Warp → Block → Grid)让开发者以直观方式表达大规模并行计算。其核心执行模型 SIMT(Single Instruction, Multiple Thread)以 Warp(32 个并行线程)为基本执行单位——与传统 SIMD 不同,SIMT 中每个线程可以跟随不同的控制流路径,硬件自动处理分支分歧(branch divergence)。
SIMT vs SIMD
SIMD(Single Instruction, Multiple Data)是单线程发出向量指令作用于数据向量;SIMT 是多线程发出共同指令但可作用于任意数据,且每个线程可以独立分支。SIMT 模型在保持高吞吐的同时提供了更灵活的编程能力,是理解 GPU 并行计算的核心概念。
同年夏天,NVIDIA 推出了 Tesla C870——首款专用 GPU 计算卡,基于 G80 架构,128 核心,1.5 GB GDDR3 显存,无视频输出,专为高性能计算(HPC)设计。"Tesla"这个名字同时指代微架构名称和计算产品品牌线,后者沿用至 2020 年退役。
深入理解 GPU 微架构¶
参考书目
本节内容主要参考 Tor M. Aamodt, Wilson Wai Lun Fung, Timothy G. Rogers 所著的 "General-Purpose Graphics Processor Architectures"(Morgan & Claypool, 2018),CoffeeBeforeArch 频道对该书有配套的视频讲解系列。该书的作者同时也是 GPGPU-Sim(最广泛引用的 GPGPU 微架构模拟器)的创建者。
要真正理解 GPU 的工作原理,需要深入其微架构层面的核心机制。以下知识点对训练营后续的 GPGPU 建模课程尤为重要。
SIMT Core 流水线¶
GPU 的 SIMT Core(即 SM/Streaming Multiprocessor)内部是一条深度流水线,其主要阶段包括:
- Fetch(取指):Warp 调度器选择一个就绪的 Warp,从 L1 指令缓存中取出其下一条指令,存入指令缓冲区(Instruction Buffer)
- Decode(译码):解析指令操作码、源/目的寄存器编号
- Issue(发射):记分板(Scoreboard)检查数据依赖,确认无 RAW/WAR 冲突后,将指令发射到执行单元
- Read Operands(读操作数):操作数收集器(Operand Collector)从寄存器文件中收集 Warp 内所有线程的源操作数
- Execute(执行):SIMD 执行单元并行处理 Warp 内 32 个线程的运算
- Writeback(写回):结果写回寄存器文件,同时更新记分板释放依赖
Warp 调度策略¶
SM 中通常有数十个活跃 Warp 同时驻留,Warp 调度器决定每个周期执行哪个 Warp。主要策略包括:
- Round-Robin(轮询):按固定顺序依次调度每个就绪的 Warp,公平但无法充分利用局部性
- GTO(Greedy-Then-Oldest):优先持续执行当前 Warp 直到其被阻塞(如等待内存),再切换到最老的就绪 Warp。GTO 在多数工作负载中性能最优,因为它最大化了单个 Warp 的缓存局部性
- Two-Level(两级调度):将 Warp 分为活跃集(Active Set)和挂起集(Pending Set),仅在活跃集内进行调度。当活跃集中所有 Warp 被阻塞时,才与挂起集交换。这种策略在缓存容量有限时能有效减少缓存抖动
分支分歧与 SIMT Stack¶
当 Warp 内的 32 个线程遇到条件分支时,如果部分线程走 if 路径、部分走 else 路径,就发生了分支分歧(Branch Divergence)。硬件通过 SIMT Stack 处理这一问题:
- 遇到分歧分支时,当前栈条目被弹出,压入三个新条目:汇合点(Immediate Post-Dominator, IPDom)、taken 路径(活跃掩码 + PC)、not-taken 路径(活跃掩码 + PC)
- 先执行栈顶路径,此时未走该路径的线程被禁用(masked off),硬件资源空转
- 该路径执行完毕后弹栈,执行另一路径
- 两条路径都完成后,在 IPDom 汇合点处所有线程重新同步(reconverge),恢复满 Warp 执行
分支分歧是 GPU 性能优化的核心挑战之一——分歧越严重,SIMD 利用率越低。理想情况下,应设计算法使同一 Warp 内的线程尽量走相同的控制流路径。
记分板与操作数收集器¶
记分板(Scoreboard)是 GPU 流水线中的依赖跟踪机制。对于生产者 - 消费者依赖(RAW),生产者指令在发射时递增计数器,在写回时递减;消费者指令在该计数器归零前必须等待。WAR 冲突的处理类似,但计数器在源操作数读取完成后递减。
操作数收集器(Operand Collector)解决了寄存器文件的带宽瓶颈。GPU 的寄存器文件通常被划分为 16 个 bank,当同一 Warp 的多个源操作数恰好落在同一 bank 时,会产生 bank 冲突并被串行化。操作数收集器充当缓冲,通过仲裁器(Arbiter)协调来自不同 Warp 的寄存器读请求,尽量将请求分散到不同 bank,从而隐藏 bank 冲突带来的延迟。
GPU 内存层次¶
GPU 拥有多层次的内存体系,理解各层的特性是编写高效 GPU 程序的关键:
| 内存类型 | 位置 | 可见范围 | 特性 |
|---|---|---|---|
| 寄存器(Register) | 片上 | 单线程私有 | 最快,数量有限,溢出到本地内存 |
| 共享内存(Shared Memory) | 片上 | Block 内共享 | 低延迟(~1-2 周期),用于线程间通信 |
| L1 缓存 | 片上 | SM 私有 | Fermi 起与共享内存可配置分配 |
| L2 缓存 | 片上 | 全局共享 | 所有 SM 共享,Fermi 起引入 |
| 全局内存(Global Memory) | 片外 DRAM | 所有线程 | 最大容量,高延迟(~400-600 周期) |
| 常量内存(Constant) | 片外(缓存在片上) | 所有线程只读 | 广播优化,适合所有线程读同一值 |
| 纹理内存(Texture) | 片外(缓存在片上) | 所有线程只读 | 优化 2D/3D 空间局部性访问 |
 GPU 内存层次结构示意图
GPU 内存层次结构示意图
内存合并访问与 Bank 冲突¶
内存合并(Memory Coalescing)是 GPU 全局内存访问的核心优化。当一个 Warp 的 32 个线程执行 load 指令时,硬件检测它们是否访问连续的内存地址。如果是,硬件将所有请求合并为一次或少数几次内存事务(burst),大幅降低有效延迟。如果地址不连续(非合并访问),硬件会将其拆分为多次独立事务,性能可能下降数倍甚至数十倍。
共享内存 Bank 冲突是另一个关键性能陷阱。共享内存被划分为 32 个 bank(每个 bank 宽度为 4 字节),每个 bank 每周期只能服务一个地址。当多个线程同时访问同一个 bank 的不同地址时,访问被串行化。最坏情况下(32 个线程访问同一 bank),延迟增大 32 倍。常见的规避策略是对数组添加 padding,使相邻线程的访问分散到不同 bank。
占用率¶
占用率(Occupancy)是衡量 SM 资源利用率的关键指标,定义为:
占用率 = 活跃 Warp 数 / SM 支持的最大 Warp 数
影响占用率的三个资源约束:
- 每线程寄存器数:使用的寄存器越多,能同时驻留的线程越少
- 每 Block 共享内存:共享内存用量越大,能同时调度的 Block 越少
- 每 SM 最大 Warp/Block 数:硬件上限
较高的占用率有助于隐藏内存延迟(因为被阻塞的 Warp 可以被其他就绪 Warp 替换),但并非总是越高越好——过高的占用率可能导致缓存抖动,反而降低性能。找到最优占用率需要结合具体工作负载分析。
架构代际演进¶
从 2006 年到 2017 年,NVIDIA 以大约每两年一代的节奏推出新架构,每一代都在计算能力、能效和功能特性上实现显著跃升。
Tesla 架构(2006)¶
G80 首发的 Tesla 架构奠定了 CUDA GPU 的基本设计范式:
- 统一着色器:128 个流处理器(后来称为 CUDA Core),以 16 个 SM(Streaming Multiprocessor)组织,每个 SM 含 8 个 SP(Stream Processor)
- SIMT 执行模型:32 个线程组成一个 Warp,由 Warp 调度器统一调度
- 2008 年的 GT200 将 CUDA Core 扩展到 240 个,并在 Compute Capability 1.3 中添加了双精度浮点支持——这是科学计算社区大规模采用 CUDA 的转折点
Fermi 架构(2010)¶
 NVIDIA Fermi (GF100) 微架构示意图,展示了 SM 阵列与内存控制器布局
NVIDIA Fermi (GF100) 微架构示意图,展示了 SM 阵列与内存控制器布局
Fermi 被称为"第一个完整的 GPU 计算架构",补齐了前代在通用计算方面的关键短板:
- ECC 内存支持:首个支持 ECC 的 GPU 架构,寄存器文件、共享内存、L1/L2 缓存和 DRAM 均受保护,满足科学计算对数据可靠性的要求
- 真正的缓存层次:每个 SM 拥有 64 KB 可配置内存(可在共享内存与 L1 缓存之间灵活分配),768 KB 统一 L2 缓存供所有 SM 共享
- 双精度浮点大幅提升:FP64 性能达到 FP32 的 1/2(专业卡),相比 Tesla 架构有数量级提升
- GF100 芯片集成 30 亿晶体管,512 个 CUDA Core
Kepler 架构(2012)¶
Kepler 引入了 SMX(Streaming Multiprocessor eXtreme),每个 SMX 包含 192 个 CUDA Core,并带来两项对 GPU 计算模型影响深远的特性:
- Dynamic Parallelism(动态并行):GPU 内核可以自行启动子内核,无需返回 CPU,减少了 CPU-GPU 通信开销
- Hyper-Q:允许多个 CPU 核心同时向单个 GPU 发送工作,支持 32 个同时的硬件管理连接队列(Fermi 仅 1 个),显著提升 GPU 利用率
- 能效优先设计:核心运行在 GPU 基础频率而非 2x 着色器频率,通过更多核心 × 更低频率实现更好的能效比
GK110 芯片集成 71 亿晶体管,28nm 工艺,满配 2880 个 CUDA Core。
Maxwell 架构(2014)¶
Maxwell 在 Kepler 相同的 28nm 工艺基础上,纯靠架构优化实现了能效革命:
- 性能/瓦特相比 Kepler 提升近 2 倍
- 重新设计的 SMM(128 个 CUDA Core),达到 Kepler 192 Core SMX 约 90% 的性能,效率翻倍
- 改进的控制逻辑分区、负载均衡和时钟门控粒度
Pascal 架构(2016)¶
Pascal 是第一个面向深度学习时代的 GPU 架构,Tesla P100 带来了多项突破性创新:
- HBM2 显存:P100 是全球首款配备 HBM2 的 GPU,4096-bit 总线宽度,720 GB/s 带宽
- NVLink 1.0:GPU-to-GPU 高速互联,双向带宽 160 GB/s,是 PCIe Gen3 x16 的 5 倍——这是 GPU 超节点互联的起点
- 混合精度计算:FP16 吞吐量达到 FP32 的 2 倍,P100 可提供 21.2 TFLOPS 的 FP16 性能,专为深度学习训练设计
- 16nm FinFET 工艺,从 28nm 的重大制程跳跃
- 150 亿晶体管,3584 个 CUDA Core
Volta 架构(2017)¶
2017 年 5 月,Tesla V100 在 GTC 2017 上发布,带来了 GPU 计算史上最重要的创新之一:
- Tensor Core:全新的专用矩阵运算单元,每个 Tensor Core 执行 4×4×4 矩阵 FMA(D = A × B + C),输入 FP16、累加 FP32。V100 的 640 个 Tensor Core 提供 120 Tensor TFLOPS,将深度学习训练性能推向新高度
- 独立线程调度:Warp 内每个线程拥有自己的程序计数器和调用栈,支持此前不可能的 Warp 内同步模式,极大简化了 CPU 代码向 GPU 的移植
- 12nm 工艺,211 亿晶体管,80 个 SM(满配 84 个)
- 32 GB HBM2 显存,900 GB/s 带宽
以下表格总结了 CUDA 时期各架构代际的关键参数:
| 架构 | 年份 | 工艺 | 晶体管 | CUDA Core | 关键创新 | 代表产品 |
|---|---|---|---|---|---|---|
| Tesla | 2006 | 90nm | 6.81 亿 | 128 | 统一着色器,CUDA | GeForce 8800 GTX |
| Fermi | 2010 | 40nm | 30 亿 | 512 | ECC, L1/L2 缓存 | GeForce GTX 480 |
| Kepler | 2012 | 28nm | 71 亿 | 2880 | 动态并行,Hyper-Q | Tesla K40 |
| Maxwell | 2014 | 28nm | — | 2048 | 能效革命 | GeForce GTX 980 |
| Pascal | 2016 | 16nm | 150 亿 | 3584 | HBM2, NVLink, FP16 | Tesla P100 |
| Volta | 2017 | 12nm | 211 亿 | 5120 | Tensor Core | Tesla V100 |
竞争生态¶
CUDA 并非 GPU 通用计算的唯一路径。2008 年,由 Apple 最初开发并提交给 Khronos Group 的 OpenCL(Open Computing Language)发布了 1.0 规范,主打跨平台、跨厂商的通用计算标准,支持 Intel、AMD、NVIDIA、ARM 等多家硬件。
然而,OpenCL 始终未能撼动 CUDA 的统治地位。作为竞争厂商联盟的产物,OpenCL 面临更新缓慢、实现碎片化的问题,而 CUDA 可以直接访问 NVIDIA 的专有硬件特性,在性能和工具链成熟度上占据优势。到 2017 年,CUDA 已占据 AI/ML 领域 80-90% 的 GPU 加速应用。
AMD 方面,2006 年发布的 Close to Metal (CTM) 和后续的 FireStream 计算产品线均未获广泛采用。2016 年,AMD 通过 ROCm 开源 GPU 计算平台发起新一轮挑战,提供 HIP 编程模型允许 CUDA 代码移植,但生态追赶仍在进行中。
深度学习的 GPU 起源¶
 AlexNet 卷积神经网络架构——5 个卷积层 + 3 个全连接层,在 2 块 GPU 上并行训练
AlexNet 卷积神经网络架构——5 个卷积层 + 3 个全连接层,在 2 块 GPU 上并行训练
2012 年 9 月,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 使用 2 块 NVIDIA GTX 580 GPU,以完全手写的 CUDA/C++ 代码训练了 AlexNet,在 ImageNet ILSVRC 竞赛中以 15.3% 的 top-5 错误率夺冠,比第二名低 10.8 个百分点。
这一事件标志着三大要素的历史性汇聚:大规模数据(ImageNet, 1200 万图像)、强大算力(GPU/CUDA)、有效架构(深度 CNN)。此后,深度学习论文数量呈爆炸式增长,GPU 从图形渲染的加速器彻底转型为 AI 时代的核心算力引擎。
2014 年,NVIDIA 发布 cuDNN——高度优化的深度学习原语库(卷积、池化、归一化等),成为 TensorFlow、PyTorch 等所有主流深度学习框架的底层加速引擎。GPU + CUDA + cuDNN 的软硬件协同,构建起了深度学习时代最重要的算力基础设施。
超节点互联(2018–至今)¶
为什么单 GPU 不再足够¶
深度学习模型的参数规模正在以远超摩尔定律的速度增长:
| 模型 | 年份 | 参数量 |
|---|---|---|
| BERT-Large | 2018 | 3.4 亿 |
| GPT-2 | 2019 | 15 亿 |
| GPT-3 | 2020 | 1750 亿 |
| PaLM | 2022 | 5400 亿 |
| GPT-4 (MoE) | 2023 | ~1.8 万亿(推测) |
以 GPT-3 级别(175B 参数)的模型为例,仅存储参数就需要 350 GB GPU 显存,加上梯度和优化器状态,训练时的总显存需求可超过 1 TB。即便是最先进的单块 GPU 也只有 80–192 GB 显存,远远不够。
为应对这一挑战,研究者发展出三种主要的多 GPU 并行策略:
- 数据并行(Data Parallelism):将模型复制到每个 GPU,分割数据批次
- 模型并行(Tensor Parallelism):将模型层内的张量切分到多个 GPU
- 流水线并行(Pipeline Parallelism):将模型不同层分配到不同 GPU
这三种策略的共同需求是:GPU 之间的高带宽、低延迟互联。PCIe 总线的带宽远远无法满足,这直接催生了 NVLink、NVSwitch 等专用互联技术的快速迭代。
架构代际演进¶
从 2018 年开始,NVIDIA GPU 架构的演进重心从单卡性能转向系统级算力扩展。
Ampere 架构(2020)¶
 NVIDIA A100 GPU (SXM4 模块)
NVIDIA A100 GPU (SXM4 模块)
2020 年 5 月发布的 A100 是 AI 数据中心的标志性产品:
- 第三代 Tensor Core:新增 TF32(TensorFloat-32)格式,无需修改代码即可获得加速;支持 BF16、FP16、INT8、INT4
- 结构化稀疏(Structured Sparsity):2:4 细粒度结构化稀疏将 Tensor Core 特定运算性能翻倍,FP16 从 312 TFLOPS 提升至 624 TFLOPS
- MIG(Multi-Instance GPU):将一块 A100 最多分为 7 个隔离的 GPU 实例,每个实例拥有独立的内存、缓存和计算资源,适合多租户推理场景
- TSMC 7nm 工艺,540 亿晶体管
- 80 GB HBM2e 显存,2 TB/s 带宽
- NVLink 3.0:12 条链路,总计 600 GB/s
Hopper 架构(2022)¶
 NVIDIA H100 GPU (SXM5 模块)
NVIDIA H100 GPU (SXM5 模块)
2022 年 3 月发布的 H100 将 AI 训练性能推向新高:
- 第一代 Transformer Engine:智能管理并动态选择 FP8 和 16-bit 计算,自动处理每层精度转换和缩放。GPT-3(175B)训练比 A100 快 4 倍,LLM 推理加速最高 30 倍
- FP8 数据类型:E4M3(范围 ±448)和 E5M2(范围 ±57344)两种格式,相比 FP16 性能提升 2 倍、内存需求减半
- TSMC 4N 工艺,800 亿晶体管
- 80 GB HBM3 显存,3 TB/s 带宽
- NVLink 4.0:18 条链路,总计 900 GB/s
Blackwell 架构(2024)¶
2024 年 3 月发布的 B200 采用双芯片封装,将 GPU 计算密度推向极致:
- 2080 亿晶体管(双 die,单 die 1040 亿),TSMC 4NP 定制工艺
- 第二代 Transformer Engine:支持 FP4(4-bit 浮点)AI 推理,使用微张量缩放(micro-tensor scaling)技术优化精度
- B200 规格:192 GB HBM3e,8 TB/s 带宽,FP4 推理 20 PFLOPS
- NVLink 5.0:18 条链路,1.8 TB/s 带宽
- B300(Blackwell Ultra, 2025):288 GB HBM3e(12-high 堆叠),FP4 密集计算 14-15 PFLOPS
Rubin 平台(2026)¶
2026 年发布的 Rubin 标志着 NVIDIA 从"GPU 公司"向"AI 基础设施平台公司"的全面转型。Rubin 不再是单一芯片,而是一个六芯片协同平台:
- Vera CPU:88 个 NVIDIA 自研 Olympus 核心(Arm 兼容),176 线程,最高 1.5 TB LPDDR5X
- Rubin GPU:3360 亿晶体管,最高 288 GB HBM4,22 TB/s 显存带宽,NVFP4 推理 50 PFLOPS
- NVLink 6 Switch:GPU 间扩展互联
- ConnectX-9:1.6 Tb/s 网络接口
- BlueField-4 DPU:基础设施处理器
- Spectrum-6 以太网交换机:跨域连接
Rubin GPU 的 NVLink 6.0 提供每 GPU 3.6 TB/s 双向带宽,是 Blackwell 的 2 倍。预计 2026 年 Q3 量产 Vera Rubin NVL72,2027 年下半年推出 Rubin Ultra NVL576(576 GPU,15 EFLOPS FP4)。
互联技术演进¶
GPU 的算力增长固然重要,但在多 GPU 协同计算场景下,互联带宽往往才是真正的性能瓶颈。
NVLink 演进¶
NVLink 从 2016 年 Pascal P100 首次引入至今,带宽增长了 22.5 倍:
| 版本 | 年份 | 搭配架构 | 每 GPU 总带宽 | 对比 PCIe |
|---|---|---|---|---|
| NVLink 1.0 | 2016 | Pascal P100 | 160 GB/s | 5× PCIe Gen3 |
| NVLink 2.0 | 2017 | Volta V100 | 300 GB/s | 10× PCIe Gen3 |
| NVLink 3.0 | 2020 | Ampere A100 | 600 GB/s | 10× PCIe Gen4 |
| NVLink 4.0 | 2022 | Hopper H100 | 900 GB/s | 14× PCIe Gen5 |
| NVLink 5.0 | 2024 | Blackwell B200 | 1,800 GB/s | — |
| NVLink 6.0 | 2026 | Rubin | 3,600 GB/s | — |
NVSwitch¶
当 GPU 数量超过两块时,点对点的 NVLink 连接无法满足"任意到任意"的全互联需求。NVSwitch 应运而生:
- 第一代(2018):搭配 Volta V100,18 个 NVLink 端口,首次用于 DGX-2(6 颗 NVSwitch 连接 16 块 GPU)
- 第二代(2020):搭配 Ampere A100,用于 DGX A100
- 第三代(2022):搭配 Hopper H100,64 个 NVLink 端口,3.2 TB/s 全双工带宽,引入 SHARP(可扩展分层聚合缩减协议)支持网内计算
- NVLink 6 Switch(2026):搭配 Rubin,28.8 TB/s 每交换托盘,支持 FP8 集体加速网内计算
DGX 系统演进¶
DGX 是 NVIDIA 的 AI 超算参考平台,其演进反映了 GPU 算力扩展的系统级趋势:
| 系统 | 年份 | GPU 配置 | GPU 总显存 | 互联 | 系统性能 |
|---|---|---|---|---|---|
| DGX-1 | 2016 | 8× P100 | 128 GB | NVLink 混合网格 | — |
| DGX-2 | 2018 | 16× V100 | 512 GB | NVSwitch 首发 | 2 PFLOPS |
| DGX A100 | 2020 | 8× A100 | 640 GB | NVLink 3.0 + NVSwitch | 5 PFLOPS FP16 |
| DGX H100 | 2022 | 8× H100 | 640 GB | NVLink 4.0 + NVSwitch | 32 PFLOPS FP8 |
| DGX B200 | 2024 | 8× B200 | 1,440 GB | NVLink 5.0 + NVSwitch | 144 PFLOPS FP4 |
InfiniBand 与 Mellanox¶
2019 年,NVIDIA 以 69 亿美元收购了 InfiniBand 领域的领导者 Mellanox Technologies(2020 年 4 月交易完成)。这一收购使 NVIDIA 同时掌握了节点内互联(NVLink/NVSwitch)和节点间互联(InfiniBand)两大关键技术:
- Quantum-2(NDR):400 Gb/s InfiniBand 交换机,64 端口,51.2 Tb/s 聚合吞吐
- Quantum-X800(XDR):800 Gb/s,144 端口
- ConnectX-7/8:400-800 Gb/s 网络适配器
超级节点与 AI 工厂¶
Grace Hopper 超级芯片¶
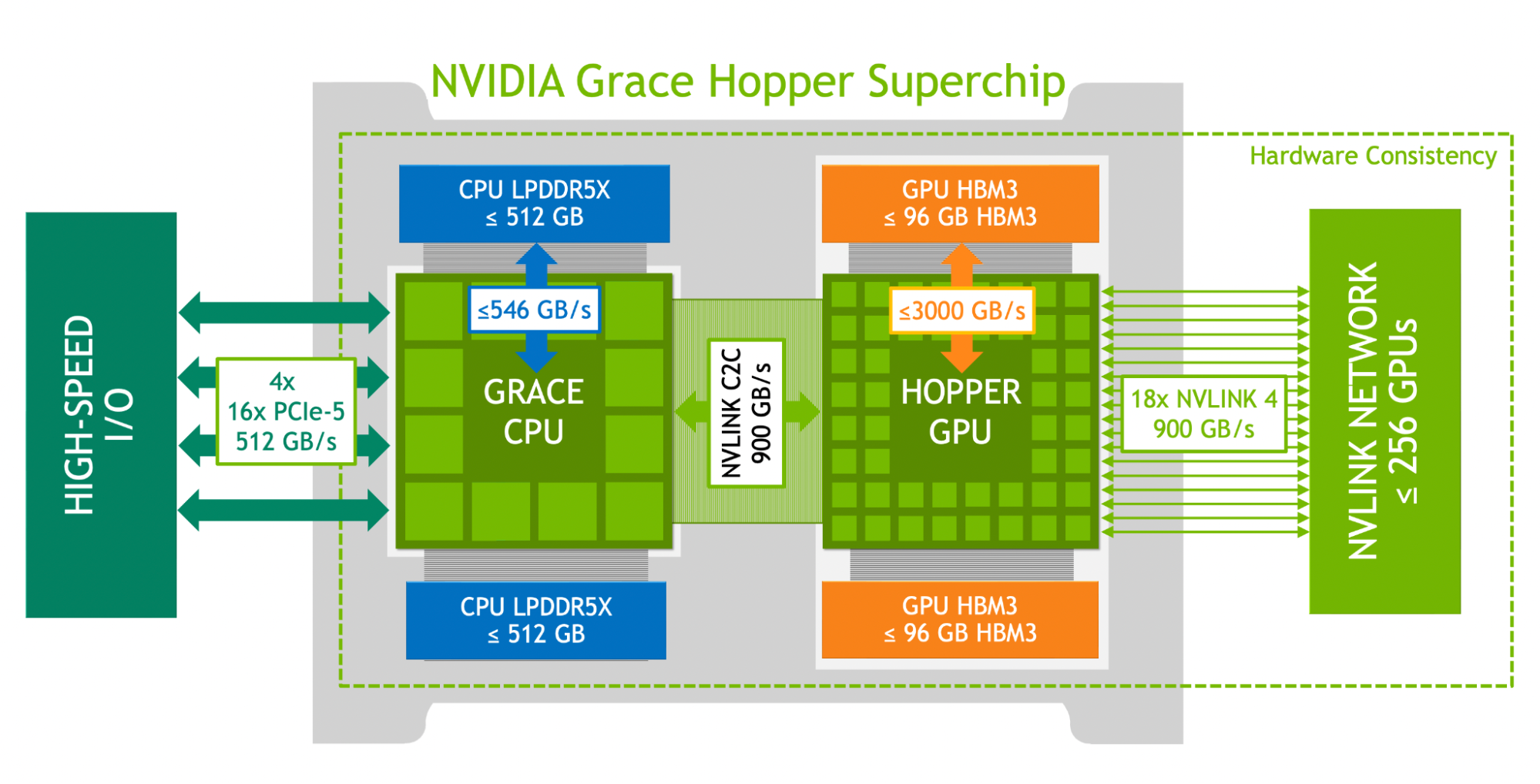 Grace Hopper 超级芯片逻辑架构——通过 NVLink-C2C 融合 CPU 与 GPU
Grace Hopper 超级芯片逻辑架构——通过 NVLink-C2C 融合 CPU 与 GPU
GH200 Grace Hopper Superchip 将 72 核 Grace CPU(Arm Neoverse V2)与 H100 GPU 通过 NVLink-C2C(Chip-to-Chip)融合,提供 900 GB/s 一致性 CPU-GPU 互联(比 PCIe Gen5 快 7 倍)。576 GB 统一一致性内存(96 GB HBM3 + 480 GB LPDDR5X)让 CPU 和 GPU 在单一地址空间中共享数据,消除了传统 PCIe 连接的数据搬运瓶颈。
GB200 NVL72¶
 GB200 NVL72 机柜级设计——72 块 GPU + 36 颗 CPU 在单一液冷机柜中
GB200 NVL72 机柜级设计——72 块 GPU + 36 颗 CPU 在单一液冷机柜中
Blackwell 时代的 GB200 NVL72 将 GPU 算力扩展提升到机柜级:
- 单一液冷机柜内集成 72 块 Blackwell GPU + 36 颗 Grace CPU
- 18 个计算节点(托盘),每个托盘含 2 个 GB200 超级芯片
- 130 TB/s NVLink 系统带宽,72 块 GPU 构成一个巨型 NVLink 域
- 支持最高 27 万亿参数的生成式 AI 模型
- 混合冷却:直接液冷 + 空气冷却,每机柜约 120 kW
DGX SuperPOD 与 AI 工厂¶
多个 NVL72 机柜可进一步组成 DGX SuperPOD:8 个 NVL72 机柜构成一个 SuperPOD(576 块 GPU),可扩展至 128+ 机柜(9,216+ GPU),每个可扩展单元功耗约 1.2 MW。
Jensen Huang 于 2022 年 GTC 首次正式提出 "AI Factory" 概念:数据中心从传统的数据存取设施,转变为 7×24 运行的智能(token)生产工厂。如同 18 世纪纺织厂或 20 世纪汽车厂一样,AI 基础设施以每 token 成本和每瓦特效用来衡量效率。到 2026 年,NVIDIA Blackwell 和 Rubin 产品线已获超过 5000 亿美元订单,"AI 工厂"已从概念变为现实。
CXL 与内存扩展¶
在 GPU 算力飞速增长的同时,内存容量和带宽正成为新的瓶颈。CXL(Compute Express Link)——基于 PCIe 物理层的高速缓存一致性互联协议,提供了一种突破内存墙的途径。
CXL 提供三个子协议:
- CXL.io:标准 I/O 通信和设备发现
- CXL.cache:允许加速器一致性缓存主机 CPU 内存
- CXL.mem:允许主机 CPU 访问外部设备上的物理内存
对于 LLM 推理场景,单 GPU 的 KV cache 往往就超过 80–120 GB。CXL 内存扩展器可作为低成本、高容量的二级存储,补充 GPU 的 HBM 显存。CXL 3.0/3.1 规范进一步支持内存池化和共享,CXL 4.0 将带宽翻倍至 128 GT/s。
与训练营课程的关联
CXL 是本训练营 AI 硬件加速建模项目的核心技术。在项目阶段,你将在 QEMU 中模拟 CXL Type-2 加速器设备,实现端到端的跨平台 GPGPU 仿真。QEMU 社区已支持 CXL Type 1/2/3 设备仿真、CXL 主机桥、交换机和内存扩展器的模拟,理解 CXL 协议是深入这些实验的重要前提。
竞争格局¶
尽管 NVIDIA 在 AI 算力领域占据主导地位,其他厂商也在积极布局:
AMD Instinct MI300X(2023):采用 CDNA 3 架构的小芯片(chiplet)设计,底层 4 个 I/O Die + 顶层 8 个加速器 Die,配备 192 GB HBM3 显存(H100 的 2.4 倍)和 5.3 TB/s 带宽,更大的内存池在大模型推理场景中具备优势。软件栈使用 ROCm 平台。
Google TPU:自研的张量处理单元,使用 ICI(Inter-Chip Interconnect)私有互联。TPU v6e(Trillium, 2024)比 v5e 峰值计算性能提升 4.7 倍,HBM 容量翻倍,每 Pod 256 芯片。TPU 深度集成于 Google Cloud,不对外销售硬件。
Intel Gaudi:Gaudi 3(2024)提供约 1.8 PFLOPS BF16/FP8 矩阵计算,功耗约 600W,集成网络用于多卡扩展,定位为成本效益替代方案。
回顾与展望¶
回顾 GPU 六十年的发展史,我们可以看到一条清晰的主线:
- 1960s–2000s:从图形加速到可编程着色器再到统一着色器架构,GPU 从"专用加速器"演变为"可编程并行处理器"
- 2006–2017:CUDA 将 GPU 的并行计算能力释放给通用程序员,深度学习的崛起确立了 GPU 作为 AI 算力引擎的地位
- 2018–至今:大模型时代推动 GPU 从单卡性能竞争转向系统级互联与扩展,NVLink、NVSwitch、DGX、SuperPOD 构建起从芯片到机柜到数据中心的完整算力层次
对于本训练营而言,理解这段历史的价值在于:
- 固定功能 vs 可编程管线的演进,解释了 GPU 从"专用"到"通用"的本质转变——这与 QEMU 中设备模拟的复杂度直接相关
- SIMT 执行模型和 Tensor Core 的工作原理,是你在专业阶段学习 GPGPU 建模课程的核心前置知识
- NVLink/CXL 等互联技术,直接关联项目阶段的 CXL Type-2 加速器仿真实验
- AI 工厂的系统级视角,帮助你理解模拟器技术在未来算力基础设施中的应用价值